OpenAI 와 AMD사이에 다년간에 걸친 6GW급 인공지능 AI GPU 공급계약이 10/6월요일 개장전에 미국을 흔들었다.
딜에대한 내용은
- 2026년에 1GW 공급계약, 주로 MI450
- 2030년까지 6GW 공급 (공급 ASP는 아직 없음)
- OpenAI는 AMD주식 160M 주를 $0.01에 매입할수 있는 warrant(신주 조건부 전환사채/인수채권)를 가짐
- 이 Warrant는 행사조건이 6GW공급이 마무리되고, AMD주가가 $600달러를 달성했을경우에 행사가 가능합니다. 행사날짜 제한도 있는데 2030년 10월 5일까지 행사되어야 합니다.
- 만약 AMD주가가 $600 찍으면 market cap이 $1T 가까이 되고, OpenAI가 가진 AMD주식은 $100B 정도됩니다.
- 뭐지 $100B정도 왕창사줘서 주가가 3배되면 다시 $100B이 생기는 또하나의 순환출자구조인가?
- 어쨋든 AMD는 손해없는 장사
내년에 1GW를 공급하려면(공급한다고 가정하면) MI450을 1M(100만개)를 OpenAI에 팔아야 하는데, 이것만 매출가격이 무려 $25B 이 됨. 다른 매출도 계속되면서 추가고 25B 이니 이게 가능하다면 주가가 쉽게 300불은 넘어야 함.
나(=시장)이 궁금한 것은 OpenAI가 달라고 한다고 줄수 있는 상황인지가 파악이 안됨. 우선 TSMC 캐파가 2026년것은 조정이 불가능한 상태임. HBM도 아직 공급부족. AMD는 재고를 너무 두려워해서 미리 주문을 확보하지도 못하는 쫄보.
만약에 낸녀에 1GW를 공급해낸다면, AMD주식은 2027녕에 이미 $600로 빠르게 근접할 수 있을것으로 생각됨.
AMD and OpenAI: The 6 Gigawatt Bet - Dr Ian Cutress
https://morethanmoore.substack.com/p/amd-and-openai-the-6-gigawatt-bet
Press Release - AMD and OpenAI Announce Strategic Partnership to Deploy 6 Gigawatts of AMD GPUs
https://ir.amd.com/news-events/press-releases/detail/1260/amd-and-openai-announce-strategic-partnership-to-deploy-6-gigawatts-of-amd-gpus
Form 8-K
https://ir.amd.com/financial-information/sec-filings/content/0001193125-25-230895/d28189d8k.htm

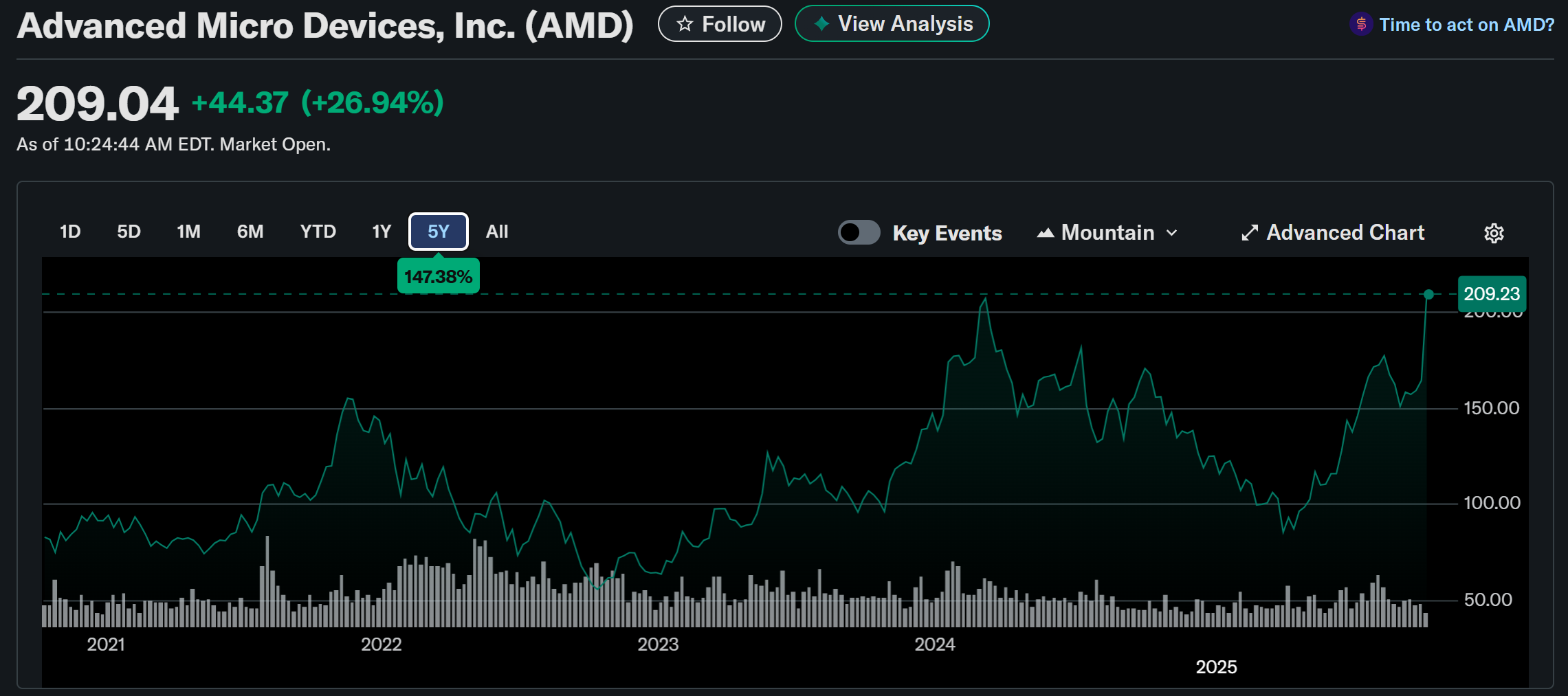

곧 2025 Q3 실적발표인데,
| Period | 2024 Revenue (Actual) | 2025 Revenue (Actual/Forecast) | YoY Growth (%) |
| Q1 | $2.34B | $3.67B (Actual) | +57% |
| Q2 | $2.80B | $3.20B (Actual) | +14% |
| Q3 | $3.55B | $3.84B (Forecast) | +8% |
| Q4 | $3.86B | $5.00B (Forecast) | +29% |
| Full Year | $12.55B | $15.71B (Forecast) | +25% |
2026년 1년 Data Center revenue가 못해도 $25B으로 forecast를 앞으로 남은 두번 실적에서 가이드를 줘야 할텐데, 그래야 계속해서 upside를 유지할수 있을듯. 25B이면 YoY가 60%되는것이고 OpenAI만 있는것은 아니니 만약에 이 보다 높게 가이드를 준다면 다시 폭등도 가능할듯. AMD의 제품이 예상대로 나오는지와 실행능력에 달려있음.
'IT이야기' 카테고리의 다른 글
| 주목해야할 새로운 브라우져 3개 (0) | 2025.05.10 |
|---|---|
| 윈도우 메모장에도 코파일럿 AI가 (0) | 2025.04.17 |
| 인텔을 인수할 가능성 높은 회사 둘? (0) | 2025.01.18 |
| 전력효율 슈퍼컴퓨터 순위 (0) | 2024.11.28 |
| 클라우드 스택 다이아그램 리스트 (0) | 2024.11.21 |